redis高可用¶
持久化¶
RDB & AOF
主从复制¶
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。复制实现了数据的多机备份以及对于读操作的负载均衡和简单的故障恢复。缺陷是故障恢复无法自动化、写操作无法负载均衡、存储能力受到单机的限制。
全量同步¶
- 从服务器向主服务器发送 sync 命令
- 收到 sync 命令后,主服务器执行 bgsave 命令,用来生成 rdb 文件,并在一个缓冲区中记录从现在开始执行的写命令。
- bgsave 执行完成后,将生成的 rdb 文件发送给从服务器,用来给从服务器更新数据
- 主服务器再将缓冲区记录的写命令发送给从服务器,从服务器执行写命令
增量同步(命令传播)¶
- 主从服务器的复制偏移量
- 主服务器的复制积压缓冲区
- 服务器的运行 id(run id)
哨兵¶
在复制的基础上,哨兵实现了 自动化 的 故障恢复。
缺陷是 写操作 无法 负载均衡,存储能力 受到 单机 的限制。
哨兵的主要功能包括 主节点存活检测、主从运行情况检测、自动故障转移、主从切换。
自动故障转移
当 主节点 不能正常工作时,
Sentinel会开始一次 自动的 故障转移操作,它会将与 失效主节点是 主从关系 的其中一个 从节点 升级为新的 主节点,并且将其他的 从节点 指向 新的主节点。配置提供者
在
Redis Sentinel模式下,客户端应用 在初始化时连接的是Sentinel节点集合,从中获取 主节点 的信息。
工作方式¶
- 每个
Sentinel以 每秒钟 一次的频率,向它所知的 主服务器、从服务器 以及其他Sentinel实例 发送一个PING命令。 - 如果一个 实例距离 最后一次 有效回复
PING命令的时间超过down-after-milliseconds所指定的值,那么这个实例会被Sentinel标记为 主观下线。 - 若主节点被标记为主管下线,所有
Sentinel节点要以 每秒一次 的频率确认 主服务器 的确进入了 主观下线 状态。 - 有 足够数量 的
Sentinel在指定的 时间范围 内同意这一判断,那么这个 主服务器 被标记为 客观下线。 - 投票自动选出新的 主节点。将剩余的 从节点 指向 新的主节点 进行 数据复制。
集群¶
集群模式自动将数据进行分片,每个 master 上放一部分数据,在多个 Redis 节点之间进行数据共享。
数据分片¶
- 一个 Redis 集群包含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。
- Redis集群通过分片的方式来保存数据库中的键值对:集群的整个数据库被分为16384个槽(slot),数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点可以处理0个或最多16384个槽。当数据库中的16384个槽都有节点在处理时,集群处于上线状态(ok);相反地,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态(fail)。换句话说,只有完全分配了16384个槽才会进入上线状态。
- 集群中的每个节点负责处理一部分哈希槽。
- 当客户端向节点发送与数据库键有关的命令时:
- 判断是否指派给自己( CRC16(key)&16383 ),执行
- 否则,返回MOVED错误,并将客户端指向正确的节点。
- 使用跳跃表来保存槽和键之间的关系,
slots_to_keys跳跃表每个节点的分值(score)都是一个槽号,而每个节点的成员(member)都是一个数据库键
故障转移¶
- 从已下线主节点中选出一个从节点
- 从节点执行SLAVEOF no one命令,成为新的主节点
- 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己。
- 新的主节点向集群广播一条PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点。
- 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
Gossip 消息¶
MEET消息:当发送者接到客户端发送的CLUSTER MEET命令时,发送者会向接收者发送MEET消息,请求接收者加入到发送者当前所处的集群里面。
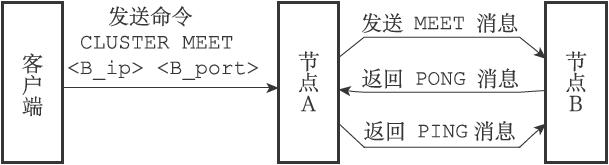
PING消息:集群里的每个节点默认每隔一秒钟就会从已知节点列表中随机选出五个节点,然后对这五个节点中最长时间没有发送过PING消息的节点发送PING消息,以此来检测被选中的节点是否在线。
PONG消息:当接收者收到发送者发来的MEET消息或者PING消息时,为了向发送者确认这条MEET消息或者PING消息已到达,接收者会向发送者返回一条PONG消息。另外,一个节点也可以通过向集群广播自己的PONG消息来让集群中的其他节点立即刷新关于这个节点的认识。
FAIL消息:当一个主节点A判断另一个主节点B已经进入FAIL状态时,节点A会向集群广播一条关于节点B的FAIL消息,所有收到这条消息的节点都会立即将节点B标记为已下线。(只包含一个nodename属性:已下线节点的名字)
每次发送MEET、PING、PONG消息时,发送者都从自己的已知节点列表中随机选出两个节点(可以是主节点或者从节点),并将这两个被选中节点的信息分别保存到两个clusterMsg-DataGossip结构里面。
接受者接收到MEET、PING、PONG消息时,根据保存的两个节点是否认识来选择进行哪种操作:
- 不认识,说明接收者第一次接触被选中节点,则接收者与被选中节点握手
- 认识,根据结构信息进行更新。
比如A节点发送的PING给B,携带了CD两个节点,然后B回复PONG携带了EF两个节点,这样就完成了ABCDEF六个节点的信息交换。每个节点按照周期向不同节点传播PING-PONG信息,就能完成整个集群的状态更新。
槽的数量:2^14¶
在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 2K),也就是说使用2k的空间创建了16k的槽数。更多的数量导致心跳包更大,不值得。
主从复制¶
集群中的每个节点都有 1 个至 N 个复制品,其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。