reids¶
快的原因¶
- 基于内存
- 专门的数据结构
- 单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
- 多路复用 epoll , 单个线程高效的处理多个连接请求
数据类型¶
字符串(Strings)¶
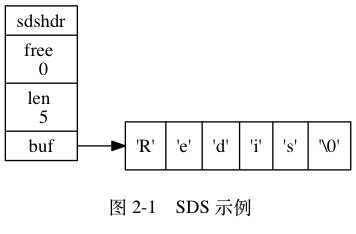
动态字符串,底层是Simple Dynamic String。字符串能包含任意类型的数据。
底层中,同样的结构使用泛型定义了多次,是为了不同长度的字符串使用不同的结构体来表示,不同长度会转换为不同的结构。
集合(Sets)¶
一个特殊的字典,字典中所有的 value 都是一个值 NULL。可以以O(1) 的时间复杂度完成添加,删除。
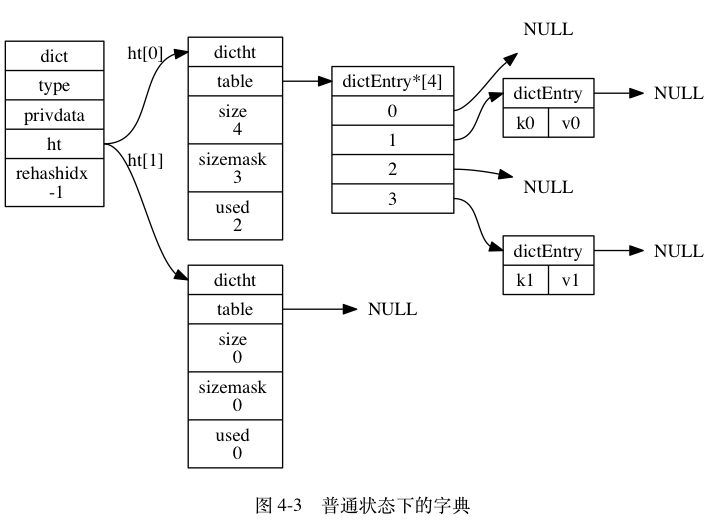
渐进式扩容¶
大字典的扩容比较耗时,需要重新申请新的空间,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个 O(n) 级别的操作。
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,如上图所示,查询时会同时查询两个 hash 结构,然后在后续的定时任务以及 hash 操作指令中,循序渐进的把旧字典的内容迁移到新字典中。当搬迁完成了,就会使用新的 hash 结构取而代之。
扩容条件¶
当 hash 表中 元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是 原数组大小的 2 倍。不过如果 Redis 正在做 bgsave(持久化命令),为了减少内存也得过多分离,Redis 尽量不去扩容,但是如果 hash 表非常满了,达到了第一维数组长度的 5 倍了,这个时候就会 强制扩容。
有序集合(zset)¶
内部实现用的是一种叫做 「跳跃表」 的数据结构。一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以为每个 value 赋予一个 score 值,用来代表排序的权重。
**O(log(N))**完成添加,删除和更新元素的操作
应用场景¶
- **String:**缓存、计数器、分布式锁等。
- **List:**链表、队列、关注人时间轴列表(可分页)等。
- **Hash:**用户信息、Hash 表等。
- **Set:**去重、赞、踩、共同好友等。
- **Zset:**访问量排行榜、点击量排行榜等。